Caveat: The following blog is about a straightforward project; however, what's important isn't the what/technology. It's the process of understanding requirements and delivering to meet business demands.
In the second instalment of this blog I want to cover something which is beautiful when implemented well. From both a developers' and operations' point of view, having a smooth process to deliver code into production is sometimes only a dream in enterprise organisations. Well, this dream is achievable!
So what's the problem we're trying to solve?
The above quote you will hear me often use and most likely through this blog series too. Our challenge is that the business and developers want to make updates to their applications regularly. For some enterprise organisations, they publish monolithic updates every 6 months, whereas small start-ups push several times a day. That is not to infer that the size of the organisation is tied to the length of delivery, this is not linear, and as an example, Amazon even back in 2015 were deploying a software release every second.
To support rapid deployments, we turn to the principals of Continuous Integration and Continuous Deployment which also encompasses Continuous Development and Continuous Testing. Not every CI/CD pipeline is the same; in fact, you should view this pipeline in a modular fashion where each step's component can be substituted for another module allowing you to pivot and use newer or different technologies when required.
Requirements
What do I need? Well, I'm running a straightforward app, so my needs match that
- Deploy changes from development quickly into production
- Easy to manage pipeline and low management overhead
- Low operating costs
The CI/CD Steps
Before jumping into my solution, I want to take a little time talking about some theory and some of the steps you should consider in any of your projects.

Step 1: SVC
Hopefully, most of you will already be familiar with Software Version Control (SVC) and the benefits that GIT, Subversion and others provide. To recap the primary purpose is to manage changes in code, thus allowing you to create a release (tag) which is a line in the sand to say "Yes, this is version x and it's good to go". However added benefits include being able to create development branches which can be independently tested before reaching the release phase.
Step 2: Continuous Integration
Once our code is in a repository, we should be looking to have an element of review by our peers so that code being deployed matches standards and patterns within the team, but also to capture any glaring issues. This phase can also include compiling the code as part of the continuous build process, which should then undertake automated unit testing. In my eyes applications can only be as good as the testing, i.e. if your testing isn't as comprehensive as your application, you are allowing more potential failures to reach production.
Step 3: Continuous Delivery
Now we have code that's been unit tested; we need to move it through into a test environment where UAT and performance testing can take place. Again, this is ideally part of an automated process where based on successful test results the release can be marked as ready to deploy into production. Most organisations consider a human brake at this point, depending on the risk level of change being applied.
Step 4: Continuous Deployment
This is the process of taking your tested application and deploying it across your production fleet using a release strategy like Blue/Green, A/B and Canary. In effect these are different ways of rolling out your application depending on your deployment risk appetite; For instance, Blue/Green can be a big bang switch-over, whereas canary is a process of gradual roll-outs.
The Solution
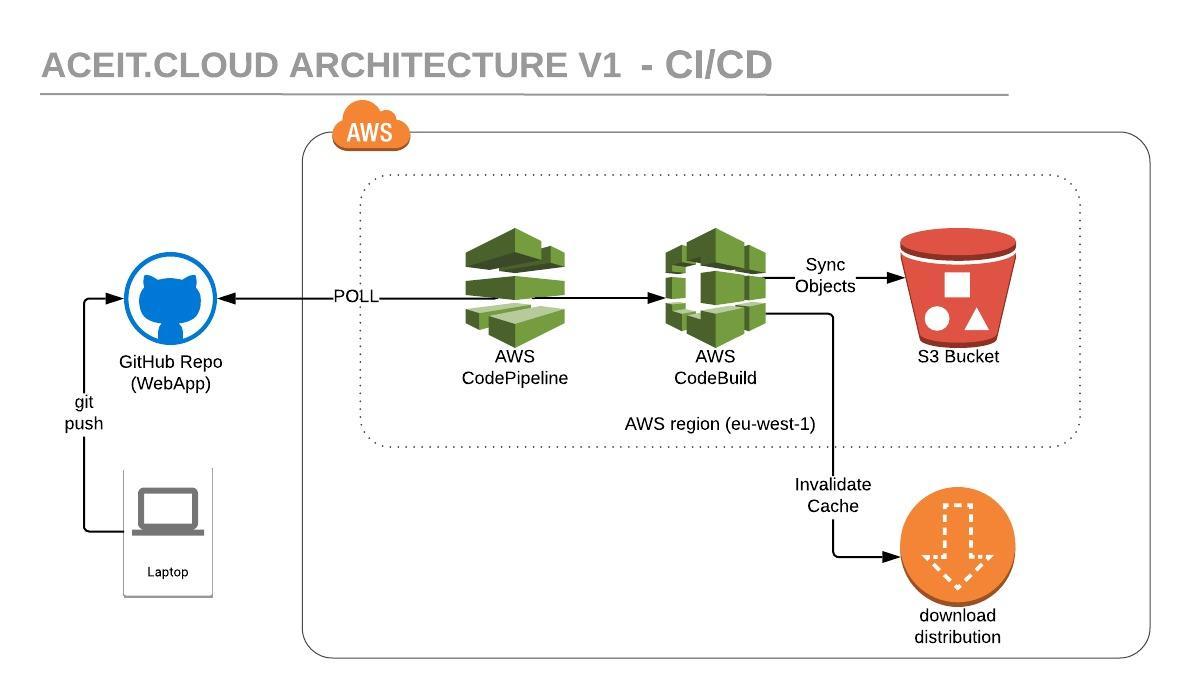
Important: I have elected to use Software-as-a-Service (SaaS) followed by PaaS for most of my technology decisions to make the best use of the cloud and cost efficiencies. I also have very little concern about vendor lock-in.
Code Repo
Which service you use comes down to your tooling strategy, in my case I have the luxury of personal preferences; so I've selected GIT, specifically GitHub Software-as-a-Service (SaaS) due to the recent update, post-Microsoft buy over, to allow free unlimited private repositories. The pipeline service has credentials to be able to poll/pull updates from the repository.
Pipeline & Deployment
In this solution I'm using the AWS Native tooling AWS CodePipeline and AWS CodeBuild. CodeBuild is reading a build spec (YAML) file in the repository which gives it the instructions for the actions to carry out at each stage. Due to my simplistic requirements, I'm only using the build phase to sync the files to S3 and invalidate the CloudFront distribution for all HTML files (enabling CloudFront to distribute the changes). The below is a copy of my build spec, I added in the other phases for demonstration purposes.
version: 0.2
phases:
install:
commands:
- echo "install step"
pre_build:
commands:
- echo "pre_build step"
build:
commands:
- aws s3 sync --delete . "s3://BUCKET_NAME" --exclude '.gitignore' --exclude 'buildspec.yml' --exclude 'README.md'
- aws cloudfront create-invalidation --distribution-id 'CF_DISTRIBUTION_ID' --paths '/*.html'
post_build:
commands:
- echo "post_build step"
Behind the scenes a very small EC2 is being spun up, pulling down the code repository and executing the above actions before being destroyed.
Operating Costs
The monthly breakdown for our new CI/CD pipeline is as follows ...
Pipeline = $1.00
CodeBuild (small) = $0.04 (1)
CDN = FREE (2)
Storage = $0.01 (3)
Total monthly cost for pipeline: $1.05
1: This assumes that I make 8 changes a month as each build process is ≤1m.
2: With CloudFront the first 1,000 invalidations per month are free.
3: Based on the number of PUT requests and additional data storage being so small.
"Tip of the iceberg."
Conclusion
This is not an advanced use case of CI/CD pipelines; however, I no longer have to access the AWS Console to make changes. This automation is an added benefit (since it reduces risk or errors as well as eliminating manual work). A production change now only takes minutes to implement and most of that time is the invalidation of the cache for existing pages.
I also haven't implemented change management, testing or a route-to-live, to name a few key capabilities - this is just the tip of the iceberg. However, as discussed on my previous blog, I am following an M.V.P approach in this series, and also I don't have the traditional ITIL requirements. That being said I will be covering and adding some of these capabilities over the coming blogs.
What's Next
Next, I'll be looking at Infrastructure-as-Code (IaC) and sharing the benefits and challenges of automated infrastructure builds.
Special mention to Fenwick Howieson for his invaluable mentoring which has given me the ability to share my story with you.
If you want some help in adopting the cloud, feel free to reach out to me using the contact details below.